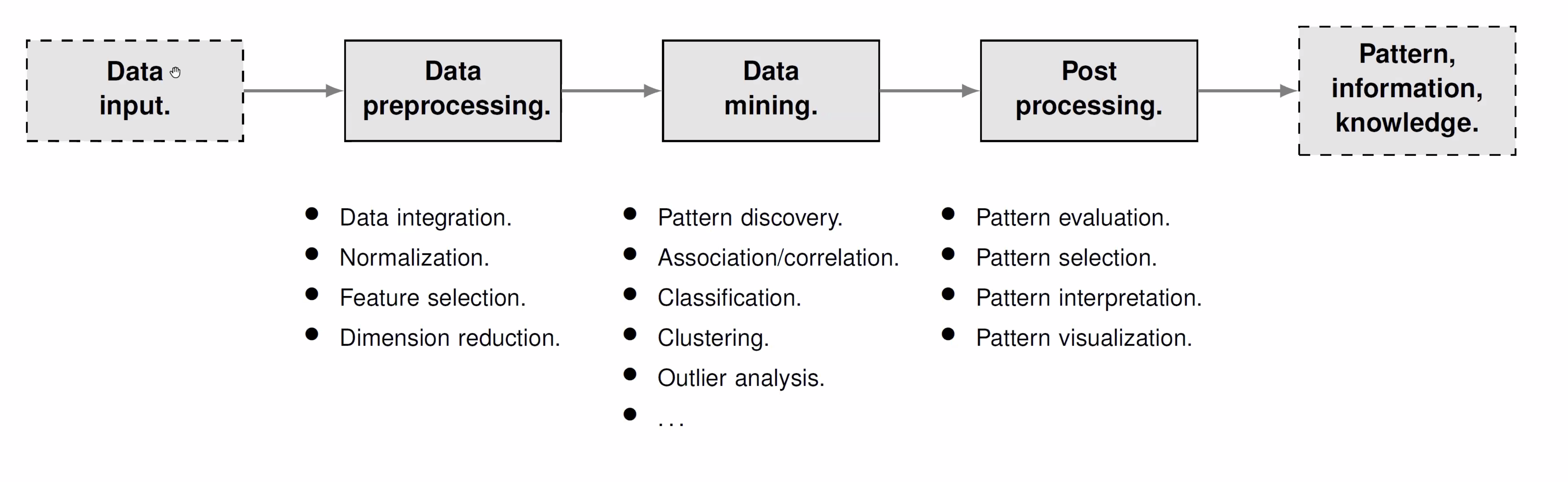
Data Mining in the ML and Statistics Community
In this ML Pipeline we go from a data input to Data Preparation which includes:
- Data Integration
- Normalization
- Feature Selection
- Dimensionality Reduction
- Data Cleaning
- Data Discretization
- …
Now we can get to the Data Mining part of the pipeline which includes:
- MOC - Pattern Recognition
- Correlation Analysis
- Classification
- Clustering
- KDD Chapter 9 Outlier Analysis
- Linear Regression / Regression
Now as one of the last steps we have post processing which includes:
- Pattern Evaluation
- Selection
- Interpretation
- and important: Data Visualization
And all of the work done in the pipeline will result in some useful information or knowledge that was gained from the data.