Log-Likelihood
Because small values are very unstable in computers, we use the Log-Likelihood. It uses a sum and applies the logarithm to every datapoint.
Rewrite Log-Likelihood by inserting the Logistic Function and applying the logarithm to the sum
then again applying the logarithm to the exponents then using the definition of the Logistic Function to get
and finally using the definition again to get
We can use this much simpler form of the equation to calculate the Gradient of the Log-Likelihood:
and the Hessian Matrix like this
We can now use the Newton Method to iteratively calculate the best parameters:
For Gaussian
We then insert the Gaussian Distribution of like this:
The Log-Likelihood can then be simplified to a negative constant times the Residual Sum of Squares (Also called the Loss) and adding another constant at the back.
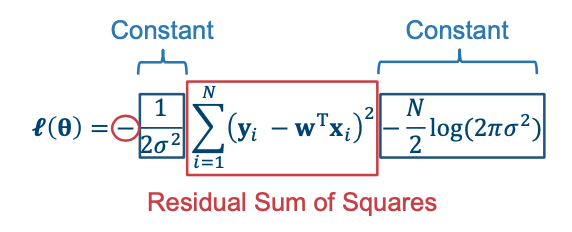
We now have a minus sign in the front. That is why we have to minimize the Residual Sum of Squares to maximize the Log-Likelihood.
The Loss is convex thus it has a unique minimum which can be calculated with:
- Gradient Descent
- Newtons Method
- Analytical solution