Local Surrogate
Used to explain individual, local predictions of a Black Box Model (thus Model-Agnostic).
Idea
Locally approximate a Black Box Model via a simpler intrinsicly interpretable model. Then generate local explanations from that model.
In contrast to Global Surrogate models local surrogate models don’t try to explain the global prediction behavior of a model but want to explain why a model made a certain prediction.
How to train local surrogate models
- Sample pertubated datapoints and predict with Black Box Model
- by pertubating the datapoint itself
- by sampling from Normal Distribution with Mean and Variance estimated from the dataset
- could also sample from other distributions or just densly sample from feature space with a grid
- Weigh each datapoint by its Proximity to the datapoint of interest
- by adding it multiple times to the dataset
- by weighing it in a model
- Train an Intrinsic interpretable model on this weighted dataset
- for example LASSO, Ridge Regression, Decision Tree
- using models with Regularisation makes a lot of sense to get simpler models which are easier to explain
- Make sure that we have high local Fidelity
- for example LASSO, Ridge Regression, Decision Tree
- Explain the datapoint by interpreting the global behavior of this new model
Mathematically
Out of all explanations (models) , find the one that minimizes the resulting explanations complexity (e.g. via LASSO) and the local loss function around the neighborhood where is the complex Black Box Model.
Visually
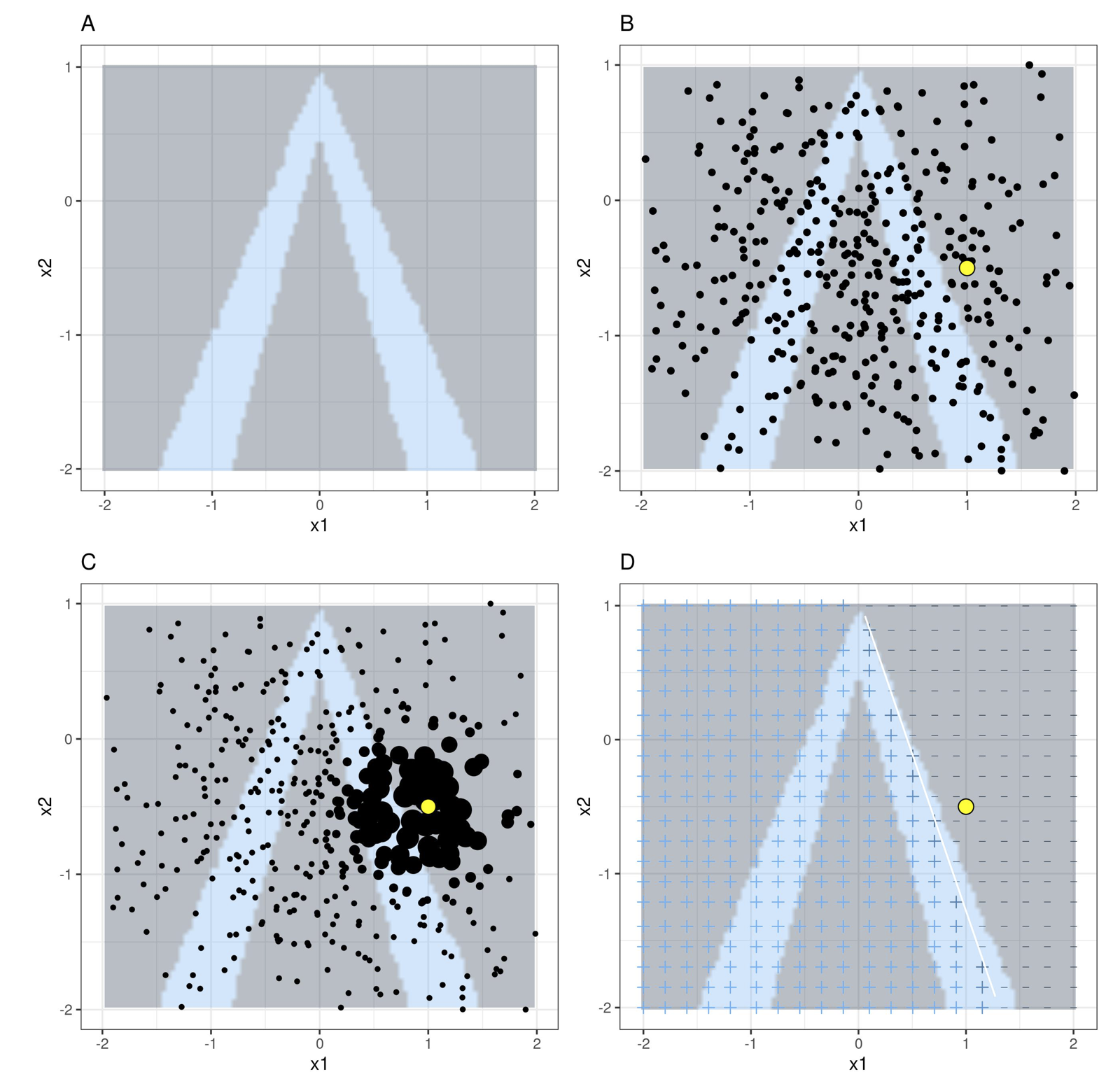
-
A → Black Box Model
-
B → Sample pertubated datapoints (Normal Distribution)
-
C → Weigh datapoints based on Proximity to point of interest
-
D → Train Intrinsic interpretable model
-
Model must have high Fidelity locally (it should match the black box predictions)
- assess with Accuracy of the interpretable model on the weighted dataset
- global fidelity can be computed when predicting on the original dataset
-
What is a good Proximity measure and how broad should the neighborhood be?
Pros
- Model-Agnostic
- human-friendly
- selective (short) explanations
- possibly Contrastive
- **works for all data types **
- Fidelity measure
- very easy to use
- can use interpretable features while the Black Box Model does not
Cons
- definition of neighborhood is a big problem
- have to try different kernels and look for best explanations
- Curse of Dimensionality, proximity measures can become useless in higher dimensions
- sampling can lead to unlikely datapoints just like in PDP
- complexity of model has to be defined in advance
- instability of explanations because of stochastic sampling
- difficult to trust explanations
- can be manipulated by data scientists