MOC - Intro to XAI
General
We differentiate between a Black Box Model and White Box Model. We want to be able to generate explanations from a model → Interpretability.
Problem with Black Box models in science
The goal of science is to gain knowledge, but many problems are solved with big datasets and black box machine learning models. The model itself becomes the source of knowledge instead of the data. Interpretability makes it possible to extract this additional knowledge captured by the model.
When do we need explainability and what do we gain from it?
In low-risk environments you might not need Explainability, e.g.
- no impact
- problem is well studied
- manipulation is unwanted (can happen when one can explain the outcome)
You need it when
- a correct prediction only partially solves the original problem.
- the task requires safety measures
- you want to detect Bias
- you need social acceptance (trust)
- you want to manage social interactions
- you want to debug or audit a model
With Explainability you also gain
- Fairness (Loan Rejection)
- Privacy
- Reliability
- Causality (in the models context)
- Trust (ChatGPT)
- Action Advice
Today, explainable machine learning can also be seen as part of the user experience by providing relevant insights into the model.
Taxonomy of Interpretability Methods and their Explanations
An interpretation method can either be
It can generate an Explanation which can be a
Averaging many local explanations can increase their scope to get global over time.
Its explanations can be
- a Feature Summary (Statistic and or Data Visualization)
- model internals (only for already interpretable models, so Model-Specific)
- learned weights
- Decision Tree
- Convolution Layers (visualized)
- data points (text + images) (could be added to your training Dataset)
Bildschirmfoto 2023-05-07 um 13.39.04.png Trade-off between Explainability and accuracy. Use better image from YouTube video hetter image from YouTube video here. todo
{kind=link}
Bildschirmfoto 2023-05-07 um 14.35.25.png
{kind=link}
Scope of Interpretability
Global, Holistic Model Interpretability
- understand the models ouputs based on its inputs, algorithm and internals
- how does the trained model make predictions
Global Model Interpretability on a Modular Level
- how do parts of the model affect predictions
- for example single weights and not all at the same time
Local Interpretability for a Single Prediction
- why was a certain prediction made
- dependence on features (linear, etc.)
Local Interpretability for a Group of Predictions
- use the others above for this
Evaluation of Interpretability
Properties of Interpretability Methods
Interpretable Models
Properties
- Linearity
- (between features and target)
- Monotonicity
- Feature-Interaction
- automatically include feature interactions
- Task
- Regression Classification or both

Linear Regression
Sometimes your data might have too many features. So we want to have sparse Linear Models (with Regularisation) like
You can use Feature Selection methods to reduce the number of features for a model to make it more interpretable.
Logistic Regression
Other linear regression extensions
When assumptions in Linear Regression are violated we can use extensions like the GLM or GAM.
Non-gaussion distributions:
Add interactions between features manually.
To get nonlinear effects we can use
- Feature Transformation (e.g. log)
- Feature Categorization / Data Discretization
- Generalized Additive Model
These extensions make linear model harder to interpret but increase their performance. Still, Random Forest or other Ensembles are better most of the time and still easier to interpret.
Decision Tree
- Decision Tree
- Linear Regression plus Decision Tree rules → RuleFit
Global Model-Agnostic Methods
Here we look at model Model-Agnostic methods that explain the global behavior of our model. So they describe the average behavior and are expressed as the expected values over the data distribution.
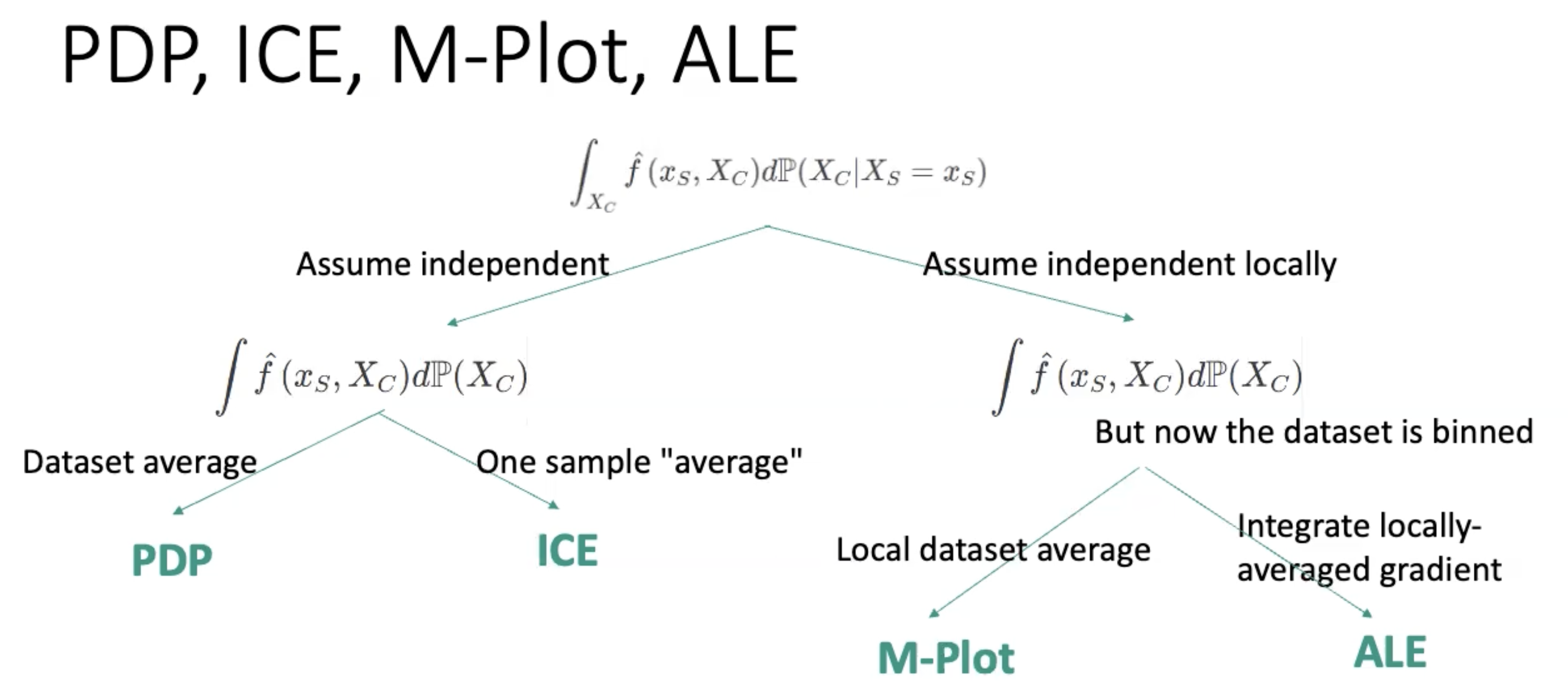
Local Model-Agnostic Mehthods
Here we look at Model-Agnostic methods that explain some local behavior, mostly an individual prediction, of our model.
Methods (all post-hoc)
- Individual Conditional Expectation Curve
- Local Surrogate (LIME)
- Counterfactual
- Shapley Values
- Shapley Additive Explanations
Neural Network
To interpret Neural Networks we can use all Model-Agnostic methods. However it makes a lot of sense to also use specific methods that take advantage of the structure of neural networks like the Gradient or Hidden Layers which can contain learned features and concepts.
Learned Features
Feature Visualization
- Global Explanation
- can be Model-Agnostic when not using gradients (they only make the optimization more efficient)
Advantages
- automatic linkage between Unit and concept with Network Dissection
- communicate Neural Networks in a non-technical way
- concepts beyond the class labels
- can be combined with feature attribution methods
Disadvantages
- many feature visualization images are not interpretabel (no human concept behind them)
- there are too mayn units to look at
- no Disentangled Features in some cases
- pixel-level segmentation datasets are needed